更: 這篇有點擔心圖片版權問題,所以先不放圖,只使用文字,之後可能再看看補上。
經過兩個禮拜終於上完了Google study jam 所指定的兩個課程,接著還有3門課可以慢慢上,但是我想利用這個星期來做點跟自己研究有點相關的作業。今天我想介紹在object detection 領域中知名的技術: yolo v1。
在computer vision的領域裡分成幾種tasks:
而yolo v1 屬於object detection的一種。Object detection又可以分成one stage或是two stage, one stage -> yolo v1, two stages -> R-CNN等等
Yolo v1 : One stage,顧名思義僅使用一個網路直接預測多個目標的類別與位置。
特點是:
快速,可以做到45FPS以上
real time
使用整張影像做訓練,背景error少。
符合 You only look once
核心想法:將目標檢測的問題轉化成一個迴歸(Regression)問題,把整張影像當作input,直接output出bounding box 的coordinate、class。
Framework:
1、將影像Resize,輸入網路;
2、執行CNN,提取特徵,輸出特徵張量;
3、對特徵張量進行非極大抑制優化(NMS),得到檢測結果。
Algorithm:
將input image分為SS個網格(grid),每一小格叫grid cell。如果一個object的中心在某個cell裡面,則該cell負責偵測這個object。
Bounding box(邊界框):
大小與位置可以用4個值來表示:(x,y,w,h),其中(x,y)是邊界框的中心座標,而w和h是邊界框的寬與高。中心座標的預測值(x,y)是相對於每個cell左上角座標點的偏移值。w和h預測值是相對於整個圖片的寬與高的比例。
每個bounding box預測5個數值(x,y,w,h,c),前4個是邊界框的大小與位置,最後一個值是該邊界框的可信度(confidence)。也就是bounding box 有沒有包含object。
Yes = 1 , No = 0。
confidence公式: 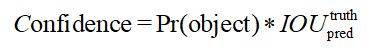
引用自Andrew Ng (如不能放請通知我移除)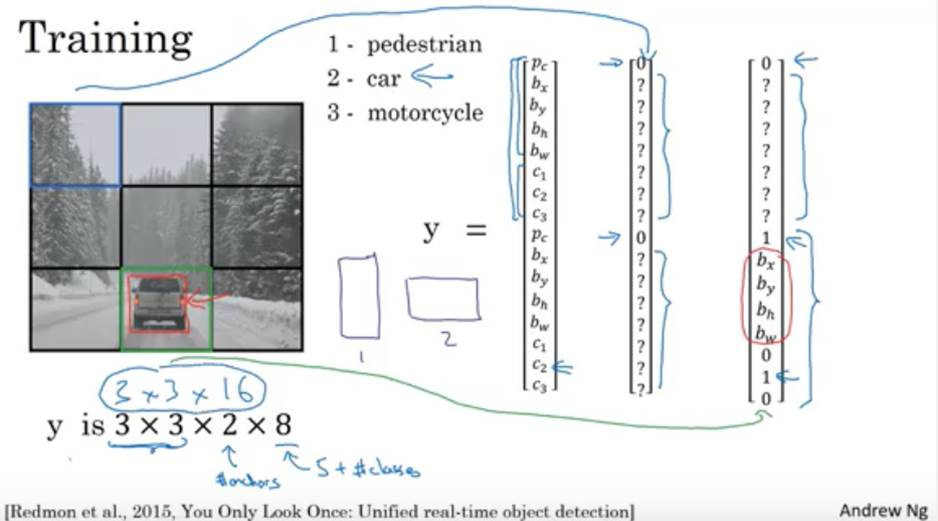
網格劃分為S×S時,最終預測值為S×S×(B∗5+C)大小的張量。
Loss function: Sum-Squared Error
引用自網路,太多人用這張圖,不清楚原作者是誰,如不能放請通知我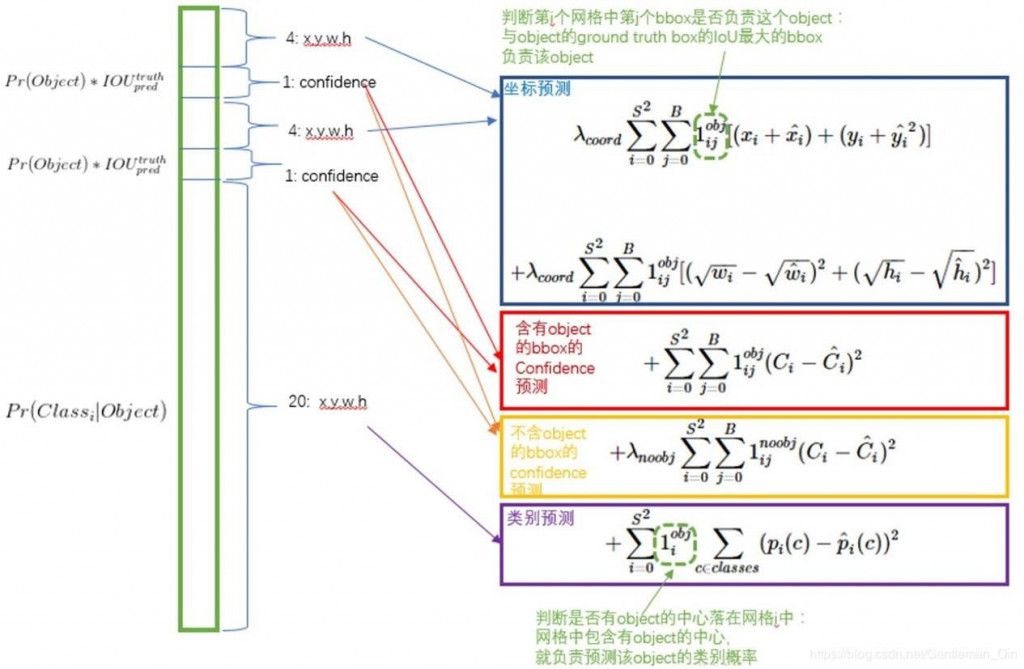
非極大值抑制演算法(Non Maximum Suppression, NMS):
主要解決的是一個目標被多次檢測的問題:
首先從所有的bounding box 中找到confidence最大的那個,然後逐個計算其與剩餘框的IOU,如果其值大於一定閾值(重合度過高),那麼就將該框剔除,然後對剩餘的bounding box重複上述過程,直到處理完所有的。
Yolo的缺點:
對靠近的物體、很小的物體檢測效果不好。
對於在物體的寬高比方面泛化率低,無法定位不尋常比例的物體

